Go back to the English version of the documentationData Virtualization中的高速缓存建议
Data Virtualization中的高速缓存建议
图 1。 高速缓存建议过程概述 
Last updated: 2024年11月26日
使用输入的查询集,Data Virtualization会推荐一个数据缓存排序列表,该列表可提高输入查询的性能,并可能有助于未来的查询工作负载。
输入查询是在前 1 天到前 15 天的任何位置运行的查询,并且执行时间必须至少为 1 分钟。 这些建议被视为在 1 天内有效,之后可以随着查询工作负载的更改而更改。
- 高速缓存建议引擎使用两个模型来生成建议。
- 基于规则的模型使用复杂的启发式方法来确定哪些高速缓存候选项可帮助输入查询工作负载。
- 基于机器学习的模型使用预先训练的机器学习模型,该模型可检测底层查询模式并预测有助于未来潜在查询工作负载的高速缓存。
这两种模型都会生成由引擎合并的高速缓存候选项的排名列表,以生成最终建议集。 您可以选择启用或禁用基于机器学习的高速缓存建议。 缺省情况下,将启用基于机器学习的高速缓存建议。
除了高速缓存创建建议之外,引擎还建议根据过去的使用情况和其他度量来高速缓存禁用和删除建议。 这些建议显示在现有高速缓存的 活动 和 不活动 高速缓存选项卡中。
- 基于机器学习的高速缓存建议会考虑底层查询模式并预测在 1 天有效的高速缓存。
Data Virtualization使用预先训练好的模型,该模型是在行业标准数据集上训练出来的。
您可以选择启用或禁用基于机器学习的高速缓存建议。
- 推荐引擎将合并两个模型中的最终推荐集并对其进行排名。 然后, 管理器 可以从这些建议添加数据高速缓存。
Data Virtualization提供了一个引擎,用于生成建议的排序列表。 高速缓存创建建议的排名由查询的执行时间,这些查询在输入工作负载中的频率以及两个模型的权重决定。 引擎完全知道并且不建议创建存在的高速缓存。 此外,引擎不会建议创建复制的高速缓存。
生成高速缓存建议的过程包含五个阶段,如下图所示:
- 收集
- 高速缓存建议引擎收集所提供时间段的查询文本,执行时间,基数,时间戳记和频率等信息。下图显示了如何过滤历史工作负载中的查询以到达建议引擎的最终输入查询集:
图 2。 高速缓存建议过程中的收集阶段。 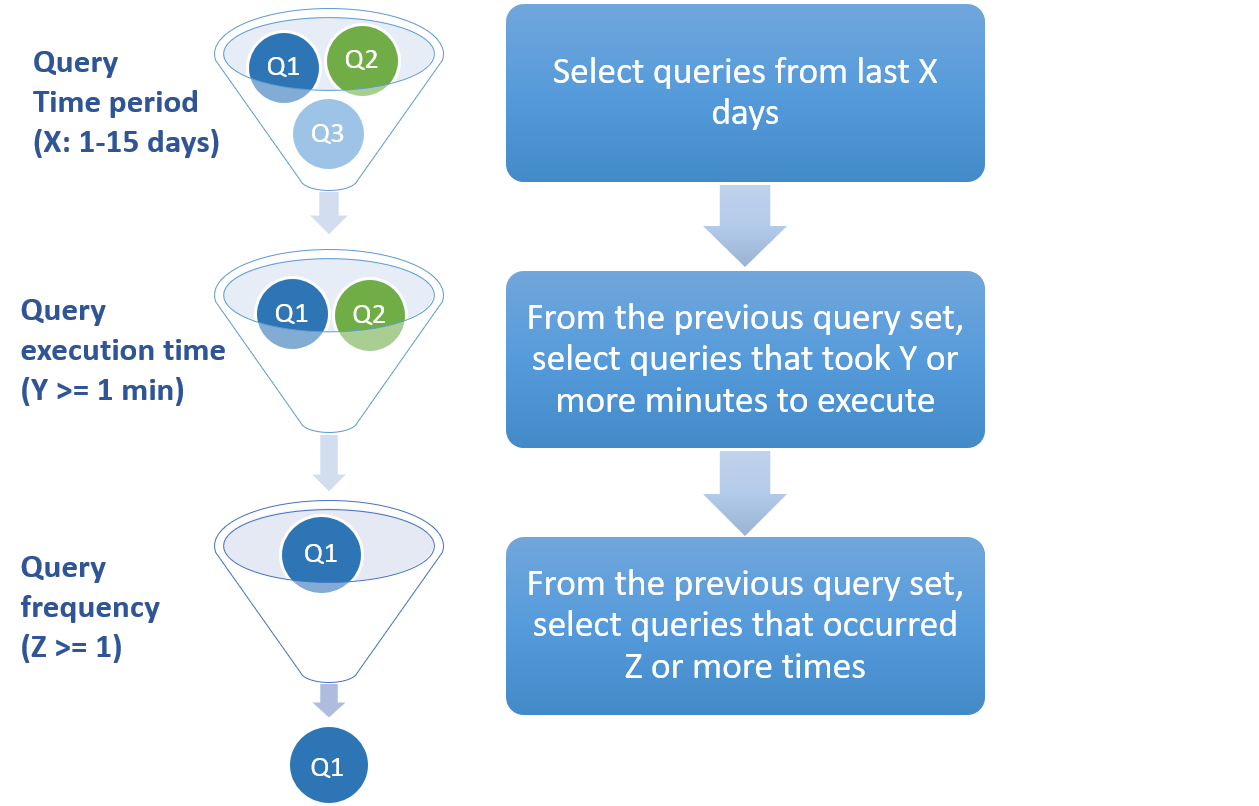
- 抽取
- 建议引擎为输入查询工作负载生成潜在的高速缓存候选项。
- 翻译
- 建议引擎会转换并合并求职者,以确保他们在语法上和语义上都正确,唯一,并通过所有 Db2® 限制。
- 评估
- 引擎通过将每个高速缓存候选值与输入查询工作负载相匹配来评估转换后的定义。 此外,为了对机器学习模型进行评分,将为每个候选者创建一个高维特征向量。
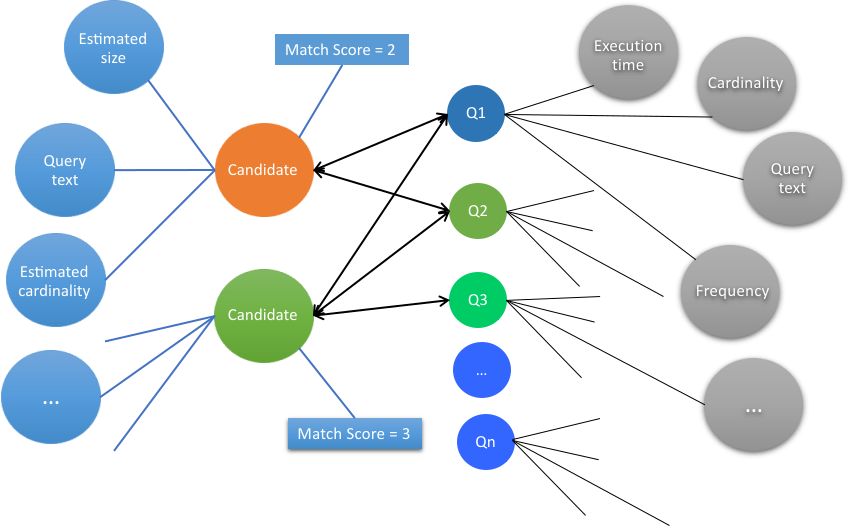
图 3。 高速缓存建议过程中的评估阶段。  作为此评估的结果,建议引擎会为每个高速缓存候选项生成匹配分数。 对每个候选人的评价都基于以下标准。
作为此评估的结果,建议引擎会为每个高速缓存候选项生成匹配分数。 对每个候选人的评价都基于以下标准。- 匹配性 与高速缓存候选值匹配的查询数。
- 多样性 与高速缓存候选值匹配的不同查询。
- 基数 高速缓存候选者访存的结果集的大小。
- 性能 高速缓存候选值匹配的查询的执行时间。
- 排名和排序
- 建议引擎对高速缓存候选项排名和排序,以生成建议的最终列表。 根据以下条件创建最终建议列表。
- 通过使用匹配的查询执行时间和频率的加权度量,对候选项排序。
- 将使用查询频率和基数打破候选项之间的任何并列排名情况。
图 4: 高速缓存建议过程中的排名和排序阶段。