Interfejs użytkownika eksperymentu Decision Optimization zawiera różne widoki , w których można wybierać dane, tworzyć modele, rozwiązywać różne scenariusze i wizualizować wyniki.
Szybkie odsyłacze do sekcji:
- Przegląd
- Konfiguracja sprzętu i oprogramowania
- Przygotuj widok danych
- Widok budowania modelu
- Wiele plików modelu
- Uruchom modele
- Konfiguracja uruchomienia
- Karta Środowisko wykonawcze
- Eksploracja widoku rozwiązania
- Panel scenariuszy
- Generowanie pliku notebooki na podstawie scenariuszy
- Importowanie scenariuszy
- Eksportowanie scenariuszy
- Dodaj plik Usługa systemu Machine Learning do projektu. Tę usługę można dodać na poziomie projektu (patrz sekcja Tworzenie instancji usługi Watson Machine Learning) lub podczas tworzenia nowego Decision Optimization eksperyment: należy kliknąć opcję Dodaj usługę systemu Machine Learning, wybrać lub utworzyć Nowa usługa, kliknąć opcję Powiąż, a następnie zamknąć okno.
- Powiąż obszar wdrażania z Decision Optimization eksperyment (patrz sekcja Obszary wdrażania). Obszar wdrażania można utworzyć lub wybrać podczas pierwszego tworzenia nowego Decision Optimization eksperymentu: kliknij opcję Utwórz obszar wdrażania, wprowadź nazwę obszaru wdrażania, a następnie kliknij opcję Utwórz. W przypadku istniejących modeli można również utworzyć lub wybrać obszar w panelu informacji Przegląd .
Po dodaniu w projekcie Decision Optimization experiment jako zasobu aplikacyjnego należy otworzyć interfejs użytkownika Decision Optimization experiment UI.
Za pomocą interfejsu użytkownika do eksperymentowania Decision Optimization można tworzyć i rozwiązywać modele optymalizacji preskryptywnej, skupiające się na konkretnym problemie biznesowym, który ma zostać rozwiązany. Aby edytować i rozwiązywać modele, użytkownik musi mieć w projekcie role administratora lub edytującego. Osoby przeglądające współużytkowane projekty mogą tylko wyświetlać eksperymenty, ale nie mogą ich modyfikować ani uruchamiać.
Model Decision Optimization można utworzyć od podstaw, wprowadzając nazwę lub wybierając plik .zip , a następnie wybierając opcję Utwórz. Zostanie otwarty scenariusz 1.
Za pomocą Decision Optimization eksperymentmożna utworzyć kilka scenariuszy z różnymi zestawami danych i modelami optymalizacji. Dzięki temu można tworzyć i porównywać różne scenariusze oraz sprawdzić, jaki wpływ mogą mieć zmiany na problem.
Szczegółowy opis budowania, rozwiązywania i wdrażania modelu Decision Optimization za pomocą interfejsu użytkownika można znaleźć w sekcji Kurs szybkiego startu z filmami wideo.
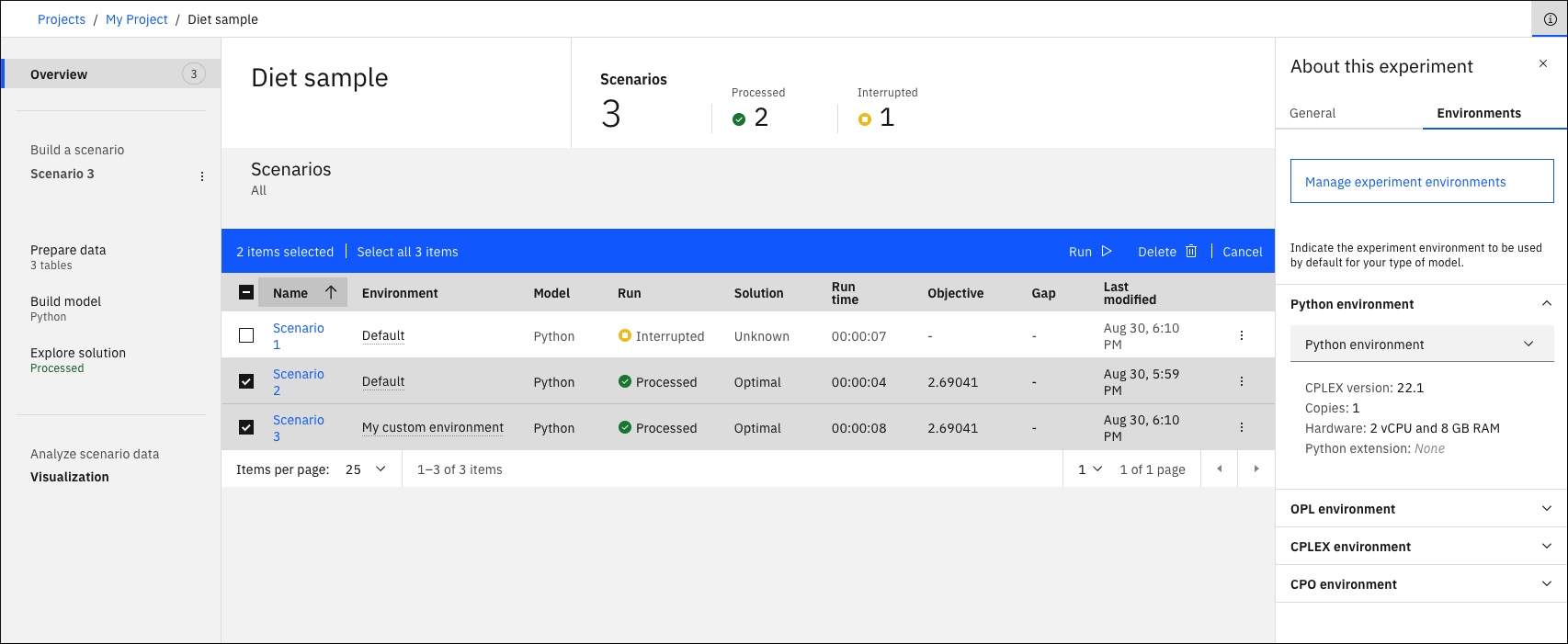
Przegląd
Karta Przegląd zawiera podsumowanie informacji o wszystkich scenariuszach. Więcej informacji na temat scenariuszy zawiera sekcja Panel scenariuszy. To podsumowanie jest przydatne w sytuacji, gdy istnieje kilka scenariuszy, ponieważ pozwala na modelowanie danych dotyczących wpływu na zmianę informacji o rozwiązaniu dla wszystkich scenariuszy w kilku słowach. Pokazuje również, czy scenariusz używa domyślnego zestawu środowiska dla tego typu modelu, czy też używa innego środowiska dla tego konkretnego scenariusza. Więcej informacji na ten temat zawiera sekcja Wybór innego środowiska wykonawczego dla konkretnego scenariusza.
- Utwórz scenariusz.
- Duplikowanie scenariusza.
- Zmień nazwę scenariusza.
- Uruchom scenariusz.
- Wyeksportuj scenariusz jako plik
.zip. - Generowanie Python notatnik na podstawie scenariusza.
- Zapisz scenariusz jako model do wdrożenia. (Typy danych ustawione w Przygotowanie danych Widok i wszystkie parametry konfiguracji uruchamiania, które mogły zostać ustawione dla tego scenariusza, są również zapisywane we wdrożeniu).
- Usuwanie scenariusza.
W tym widoku po kliknięciu ikony informacji  zostanie otwarty panel informacji zawierający szczegółowe informacje o eksperymencie oraz nazwę powiązanego obszaru wdrażania. W tym miejscu można utworzyć Usługa systemu Machine Learning , a nawet dodać tę usługę do projektu, jeśli jeszcze tego nie zrobiono. Można również utworzyć lub wybrać obszar wdrażania dla eksperymentu , aby można było użyć innego obszaru dla konkretnego rozwiązania. W tym miejscu podano również datę i nazwę twórcy eksperymentu . Ta informacja jest przydatna w przypadku współużytkowania eksperymentu utworzonego przez innego współpracownika.
zostanie otwarty panel informacji zawierający szczegółowe informacje o eksperymencie oraz nazwę powiązanego obszaru wdrażania. W tym miejscu można utworzyć Usługa systemu Machine Learning , a nawet dodać tę usługę do projektu, jeśli jeszcze tego nie zrobiono. Można również utworzyć lub wybrać obszar wdrażania dla eksperymentu , aby można było użyć innego obszaru dla konkretnego rozwiązania. W tym miejscu podano również datę i nazwę twórcy eksperymentu . Ta informacja jest przydatna w przypadku współużytkowania eksperymentu utworzonego przez innego współpracownika.
Panel informacji zawiera również kartę Środowisko . W tym miejscu można wyświetlić domyślne środowisko wykonawcze, które jest używane do rozwiązywania po kliknięciu opcji Uruchom w Budowanie modelu Widok. Środowisko zależy od typu modelu. Modele Modeling Assistant wymagają środowisk Python . Patrz sekcja Konfiguracja sprzętu i oprogramowania.
Można uruchomić lub usunąć wiele scenariuszy w tym oknie Przegląd , wybierając je i klikając opcję Uruchom lub Usuń. Te przyciski są widoczne tylko po dokonaniu wyboru. Jeśli nie można uruchomić co najmniej jednego scenariusza (na przykład z powodu braku utworzonego środowiska), przycisk Uruchom jest niedostępny. Jednak podpowiedź zawiera informacje o tym, dlaczego nie można uruchomić scenariusza. Uruchomienie można również zatrzymać z poziomu panelu Przegląd , klikając przycisk zatrzymania, który jest wyświetlany podczas działania scenariusza.
Można również skonfigurować ten panel Przegląd , klikając ikonę Ustawienia  . To działanie powoduje otwarcie panelu, w którym można wybrać kolumny, które mają być wyświetlane w panelu Przegląd . Można dodać ustawienia mechanizmu jako kolumnę dla modeli OPL, a w tym przypadku w tabeli pojawi się wartość yes . Po kliknięciu tej wartości zostaną wyświetlone ustawienia mechanizmu .
. To działanie powoduje otwarcie panelu, w którym można wybrać kolumny, które mają być wyświetlane w panelu Przegląd . Można dodać ustawienia mechanizmu jako kolumnę dla modeli OPL, a w tym przypadku w tabeli pojawi się wartość yes . Po kliknięciu tej wartości zostaną wyświetlone ustawienia mechanizmu .
Konfiguracja sprzętu i oprogramowania
Jeśli używany jest interfejs użytkownika eksperymentu, automatycznie tworzone są niezbędne środowiska. Można jednak skonfigurować środowisko, które będzie używane do rozwiązywania problemów, zmieniając środowisko domyślne. To środowisko zostanie następnie zastosowane do wszystkich scenariuszy w eksperymencie. Środowisko zależy od typu modelu: Python, OPL, CPLEX, CPO lub Modeling Assistant (wykorzystujący środowiska Python ). Na przykład, aby zmienić domyślne środowisko Python dla modeli DOcplex i Modeling Assistant , patrz sekcja Konfigurowanie środowisk i dodawanie rozszerzeń Python. Przedstawiono także sposób wybierania innego środowiska wykonawczego dla konkretnego scenariuszabez zmiany wartości domyślnej dla wszystkich innych scenariuszy.
Środowisko Decision Optimization obsługuje obecnie język Python 3.10. Wersja domyślna to Python 3.10.
Dla każdego z poniższych widoków można zorganizować ekran w postaci pełnoekranowego lub podzielonego ekranu. W tym celu należy umieścić wskaźnik myszy nad jedną z kart widoku (Przygotuj dane, Buduj model, Eksploruj rozwiązanie) dla sekundy lub dwóch. Zostanie wyświetlone menu, w którym można wybrać opcję Pełny ekran, Do lewej lub Do prawej. Jeśli na przykład jako Przygotowanie danych Widokzostanie wybrana opcja Lewa , a następnie jako Poznaj rozwiązanie Widokzostanie wybrana opcja Z prawej , oba te widoki będą wyświetlane na tym samym ekranie.
przygotowywanie danych widok
Podczas tworzenia nowego Decision Optimization eksperyment w projekcie otwierany jest Przygotowanie danych Widok . W tym widoku można przeglądać i importować zestawy danych, w tym połączone dane, które znajdują się już w projekcie. Można również dodać dane, które mają zostać dodane do projektu. Kliknij opcję dodaj dane , a następnie kliknij przycisk Przeglądaj w otwartym panelu danych. Przejrzyj i wybierz pliki, a następnie kliknij przycisk Otwórz , aby je dodać. Po dodaniu zestawu danych w ten sposób jest on wyświetlany w widoku Przygotowanie danych Widok oraz w pliku Zasoby danych znajdującym się na liście w projekcie.
Wybierz pliki, które mają zostać zaimportowane do obszaru Scenariusz i kliknij opcję Importuj. Można importować pliki w większości formatów, w tym pliki .csv, .xls, .json i połączone dane. Jeśli używane są pliki Excel z wieloma arkuszami, zostanie zaimportowany tylko pierwszy arkusz. Każdy arkusz można jednak wyeksportować jako plik .csv w celu zaimportowania danych do produktu Decision Optimization eksperyment.
.cvs zawiera szkodliwy ładunek (na przykład formuły) w polu wejściowym, te elementy mogą zostać wykonane.Po zmodyfikowaniu, zastąpieniu lub usunięciu zestawu danych w projekciete działania nie będą miały wpływu na scenariusz, chyba że zostanie wybrana opcja zaimportowania tego zestawu danych do scenariusza. Podobnie, jeśli zostanie ponownie przesłana nowa wersja tabeli przy użyciu przycisku dodawania danych w oknie Przygotowanie danych Widok, nie będzie to miało wpływu na scenariusz, chyba że zostanie on Import wybrany w scenariuszu.
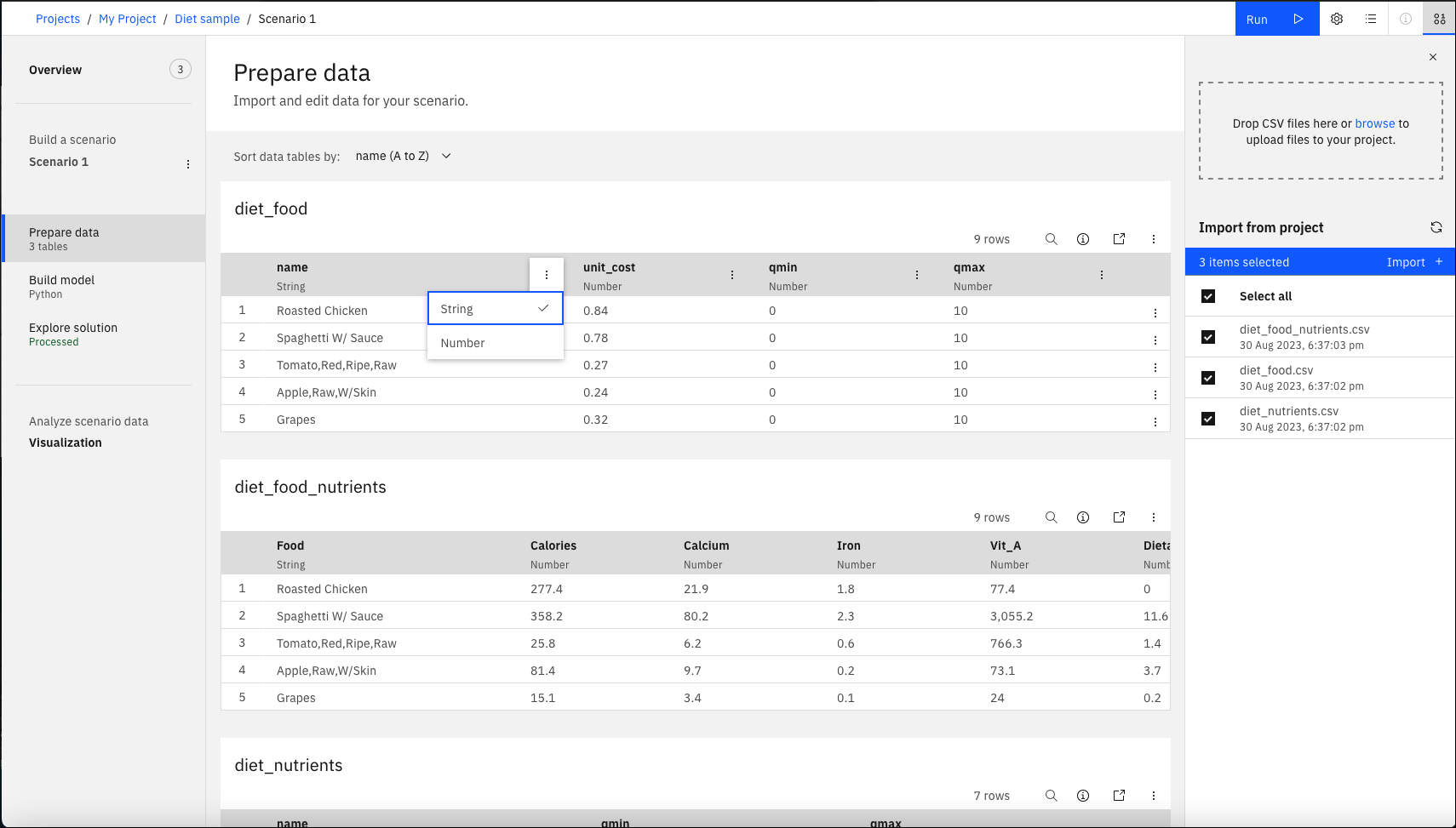
- Zmień nazwę lub usuń tabelę.
- Dane można edytować bezpośrednio w tabeli. Można przewinąć tabelę, aby wyświetlić więcej wierszy (lub otworzyć tabelę w trybie pełnym, aby wyświetlić całą tabelę i edytować ją w nowym oknie).
- Zmień nazwy kolumn.
- Zmień wielkość kolumn.
- Zmień typ danych (liczba lub łańcuch) kolumny. (Te typy są używane podczas zapisywania scenariusza jako modelu do wdrożenia).
- Dodaj lub usuń wiersze.
- Wyszukiwanie i filtrowanie wartości w tabeli. Patrz sekcja Wyszukiwanie i filtrowanie tabeli.
- Sortowanie tabel.
- Eksportuj tabele do projektu.
- Uruchom model.
Jeśli plik zostanie ponownie zaimportowany w dowolnym momencie, można go zaimportować z nową nazwą. Ta zmiana nazwy może być przydatna, jeśli mają być używane różne wersje tej samej tabeli danych. Można również wybrać opcję aktualizacji i nadpisania bieżącej tabeli w scenariuszu. Jeśli zostanie wybrana opcja ponownego importowania i aktualizowania tabeli, zostanie wyświetlony komunikat z powiadomieniem o tym, które tabele zostały nadpisane.
Zmiany wprowadzone w Przygotowanie danych Widok zostaną zapisane w scenariuszu, ale nie w zasobach danych projektu, chyba że tabela zostanie wyeksportowana do projektu. Podobnie, jeśli zasoby aplikacyjne danych projektu zostaną zmodyfikowane, o ile te zmiany nie zostaną zaimportowane do scenariusza, nie będą one wyświetlane w oknie Przygotowanie danych Widok.
Aby wyeksportować tabelę do projektu, należy kliknąć trzy kropki i wybrać opcję Eksportuj do projektu. Zostanie otwarte nowe okno, w którym można wprowadzić nazwę pliku i wybrać opcję utworzenia nowego zasobu aplikacyjnego danych projektu lub zastąpienia istniejącego. Jeśli zostanie wybrana opcja nadpisania połączonego pliku danych, tabela w połączeniu również zostanie zaktualizowana. 
Przykład zawierający eksportowanie tabel można znaleźć w sekcji CopyAndSolveScenarios notatnik w folderze Jupyter w pliku DO-przykłady w katalogu Decision Optimization GitHub.
Dostęp do zaimportowanych danych z modelu DOcplex Python można uzyskać za pomocą składni inputs['tablename']. Patrz Dane wejściowe i wyjściowe.
Buduj model widok
Po pierwszym kliknięciu ikony Buduj model na pasku bocznym zostanie wyświetlone okno, w którym można wybrać sposób formułowania modelu. W programie Modeling Assistantmożna wybrać tryb asysty lub utworzyć lub zaimportować model w języku Python, OPL, LP (CPLEX) lub w kodzie CPO.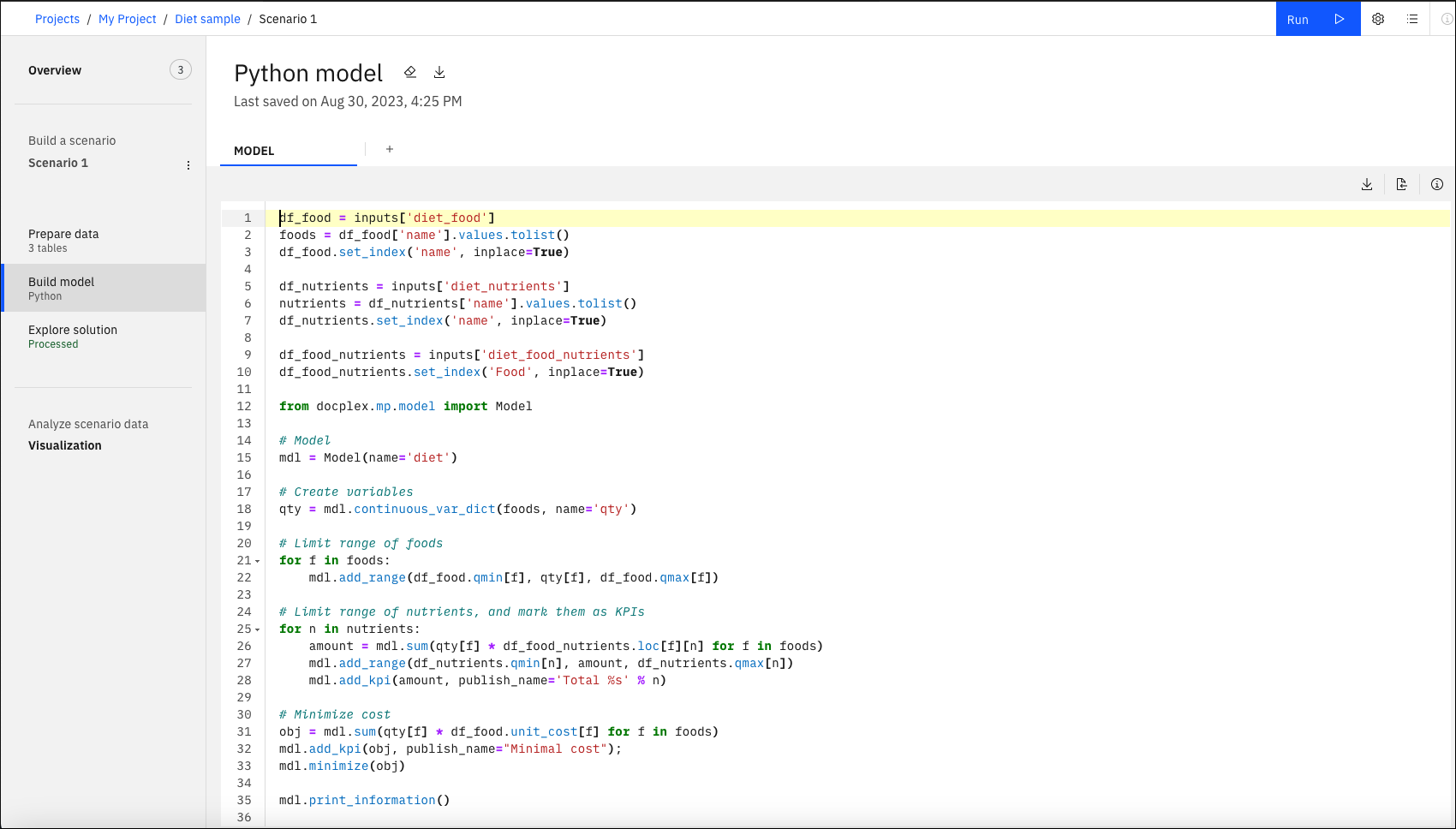
W tym widokumożna formułować lub importować modele optymalizacji i je uruchamiać.
Istnieje kilka opcji tworzenia modelu:
- Utwórz i edytuj model Python lub OPL w Decision Optimization interfejs użytkownika eksperymentu. Patrz modele OPL.
- Modeling Assistant służy do formułowania modeli w języku naturalnym. Kurs tworzenia modeli za pomocą Modeling Assistantzawiera sekcja Formuły i uruchamianie modelu: planowanie budowy domu .
- Importowanie i edytowanie modelu optymalizacji Python z istniejącego notebook. Ta opcja służy do importowania notatnika z projektu. Jeśli notatnik działa w dostosowanym środowisku Jupyter (patrz sekcja Dodawanie dostosowania), podczas importowania pliku notebook do interfejsu użytkownika eksperymentunależy również zaimportować tę definicję środowiska. Dlatego można użyć dodatkowych bibliotek Python podczas uruchamiania modeli z interfejsu użytkownika eksperymentu. Ta niestandardowa definicja oprogramowania będzie również używana podczas wdrażania modelu w produkcie Watson Machine Learning (zarówno po zapisaniu modelu do wdrożenia, jak i po awansowaniu go do obszaru wdrażania).
- Importowanie i edytowanie modelu optymalizacji Python z pliku zewnętrznego. Użyj tej opcji, aby zaimportować plik Python z komputera lokalnego.
- Importuj i edytuj model OPL z pliku.
- Importuj i edytuj model CPLEX z pliku.
- Import i plik scenario.zip (zawierający zarówno model, jak i dane). Ten plik może być nowym scenariuszem lub plikiem wyeksportowanym wcześniej z Decision Optimization eksperymentalnego interfejsu użytkownika i edytowanym lokalnie.
- Wygeneruj model Python na podstawie bieżącego scenariusza (tylko modelePython i Modeling Assistant ). Spowoduje to utworzenie w projekcie modelu optymalizacji Python notebook .
Podczas edycji sformułowania modelu w Decision Optimization interfejsie użytkownika eksperymentu treść jest zapisywana automatycznie i wyświetlana jest wartość Czas ostatniego zapisu .
Po utworzeniu modelu zostanie wyświetlona strzałka Zastąp ![]() . Po kliknięciu tej strzałki zastępowania nastąpi powrót do kreatora modelu. Należy zauważyć, że jeśli zostanie utworzony nowy model, poprzedni zostanie usunięty.
. Po kliknięciu tej strzałki zastępowania nastąpi powrót do kreatora modelu. Należy zauważyć, że jeśli zostanie utworzony nowy model, poprzedni zostanie usunięty.
Po zakończeniu edycji modelu można go rozwiązać, klikając przycisk Uruchom w tym widoku.
Wiele plików modelu
Modele Python lub OPL można utworzyć przy użyciu wielu plików modelu, klikając kartę + obok opcji MODELi wybierając opcję Dodaj nowe puste lub Prześlij pliki (w celu dodania dowolnego typu pliku). Karta MODEL musi zawsze zawierać model główny. Jeśli zostanie podjęta próba przesłania innego pliku o takiej samej nazwie, na przykład model.py, zostanie wyświetlona prośba o przesłanie go z nową nazwą lub o zastąpienie modelu głównego. Model można również zastąpić, klikając ikonę Importuj  . Patrz przykład Multifile w folderze Model_Builder w katalogu DO-samples.
. Patrz przykład Multifile w folderze Model_Builder w katalogu DO-samples.
Uruchom modele
Aby uruchomić modele, należy powiązać instancję produktu Watson Machine Learning z projektem i powiązać obszar wdrażania z eksperymentemproduktu Decision Optimization . Użytkownik musi mieć również rolę Edytujący lub Administrator w obszarze wdrażania.
W przypadku uruchamiania modelu z poziomu interfejsu użytkownika eksperymentuproduktu Decision Optimization środowisko wykonawcze do_22.1 jest domyślnie używane.
Można wyświetlić i zmienić środowisko wykonawcze CPLEX oraz środowisko Python w eksperymencie Przegląd , otwierając kartę Środowisko w panelu Informacje i wybierając jedno z dostępnych środowisk dla danego typu modelu (Python, OPL, CPLEX, CPO). Python służy do uruchamiania modeli Decision Optimization , które zostały sformułowane w programie DOcpleks zarówno w eksperymentach Decision Optimization , jak i w eksperymentach Jupyter notebooki. Modele Modeling Assistant używają również języka Python , ponieważ kod DOcplex jest generowany podczas wdrażania modeli.
Niektóre parametry optymalizacji można również ustawić i zmodyfikować, klikając ikonę Skonfiguruj uruchomienie znajdującą się obok przycisku Uruchom . Te parametry zostaną zastosowane po każdym kliknięciu przycisku Uruchom. Więcej informacji na ten temat zawiera sekcja Konfiguracja uruchamiania.
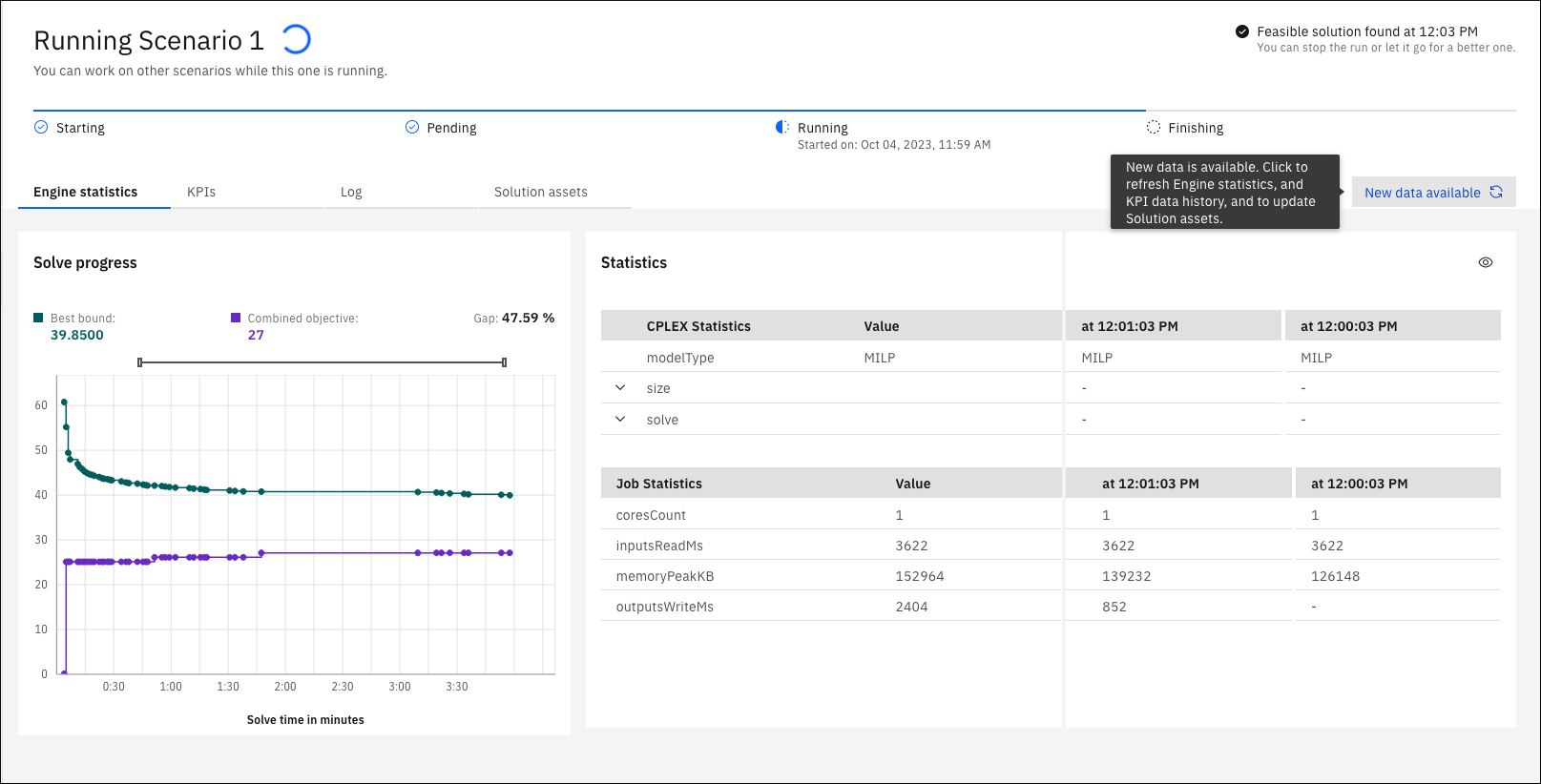
Podczas wykonywania wyświetlany jest graficznie obraz możliwych rozwiązań, które są uzyskiwane do momentu znalezienia optymalnego rozwiązania. Jeśli parametr intermediate solution delivery w konfiguracji wykonywania został ustawiony na określoną częstotliwość, wyświetlana jest próbka rozwiązań pośrednich z tą częstotliwością. Aby wyświetlić te rozwiązania pośrednie, należy kliknąć opcję Nowe dostępne dane. Jednocześnie wyświetlane są maksymalnie 3 rozwiązania pośrednie. Za pomocą kart można wyświetlić Statystyki mechanizmu,, kluczowe wskaźniki wydajności, plik dziennika , a tabele rozwiązania ostatniego rozwiązania próbkowanego można wyświetlić na karcie Zasoby rozwiązania . Aby uzyskać rozwiązania pośrednie dla modeli Python DOcplex, należy zaimplementować konkretne wywołanie zwrotne w modelu. Patrz przykład IntermediateSolutions w folderze Model_Builder w sekcji DO-samples w serwisie Decision Optimization GitHub. Wybierz odpowiedni podfolder produktu i wersji.
Konfiguracja uruchomienia
Po kliknięciu Skonfiguruj uruchomienie ikony  obok przycisku Uruchom w Budowanie modelu Widokzostanie otwarte okno zawierające aktualnie ustawione wartości parametrów.
obok przycisku Uruchom w Budowanie modelu Widokzostanie otwarte okno zawierające aktualnie ustawione wartości parametrów.
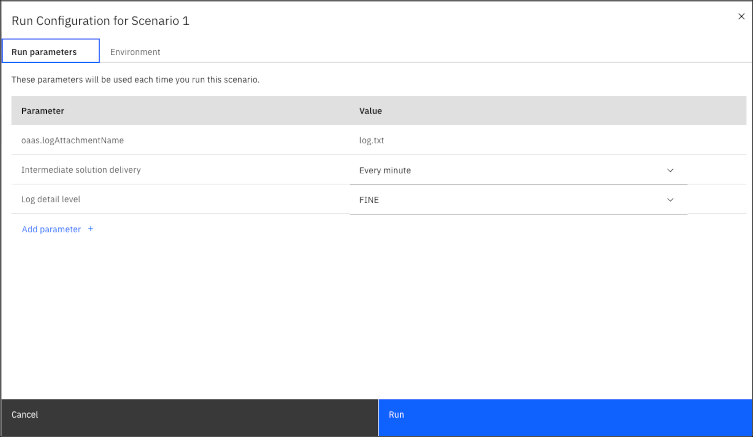
W tym miejscu można wybrać i edytować różne parametry konfiguracji uruchamiania. Więcej informacji na ten temat zawiera sekcja Parametry uruchamiania.
Po ustawieniu parametrów konfiguracyjnych uruchamiania będą one używane z tymi wartościami dla wszystkich kolejnych uruchomień tego scenariusza.
Można usunąć ustawione parametry, umieszczając wskaźnik myszy nad parametrem i klikając ikonę Usuń .
Na karcie Środowisko w tym panelu wyświetlane jest domyślne środowisko wykonawcze używane na potrzeby eksperymentu. 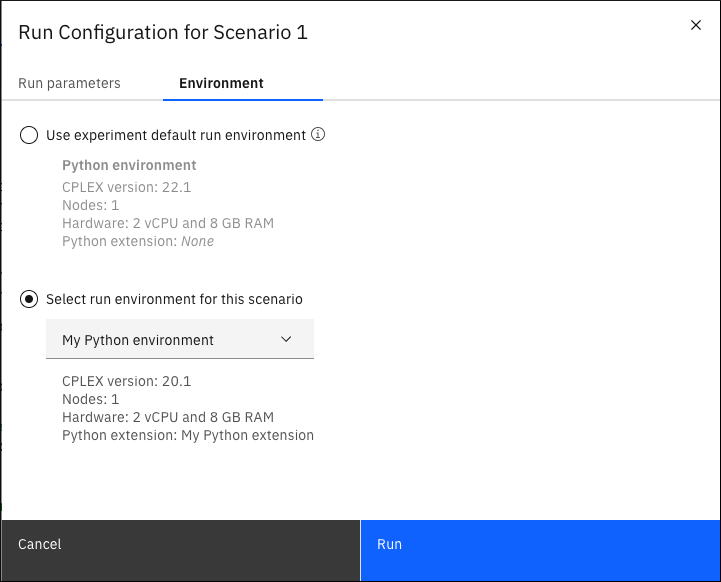
Po rozwiązaniu modelu przez kliknięcie opcji Uruchomużywane jest to środowisko domyślne lub, jeśli nie istnieje, jest ono tworzone automatycznie. Typ używanego środowiska zależy od typu modelu (Python, OPL, CPLEX, CPO, Modeling Assistant). Więcej informacji na ten temat zawiera sekcja Karta Środowisko w panelu Informacje o przeglądzie. Można również skonfigurować środowiska.
Eksploracja rozwiązania widok
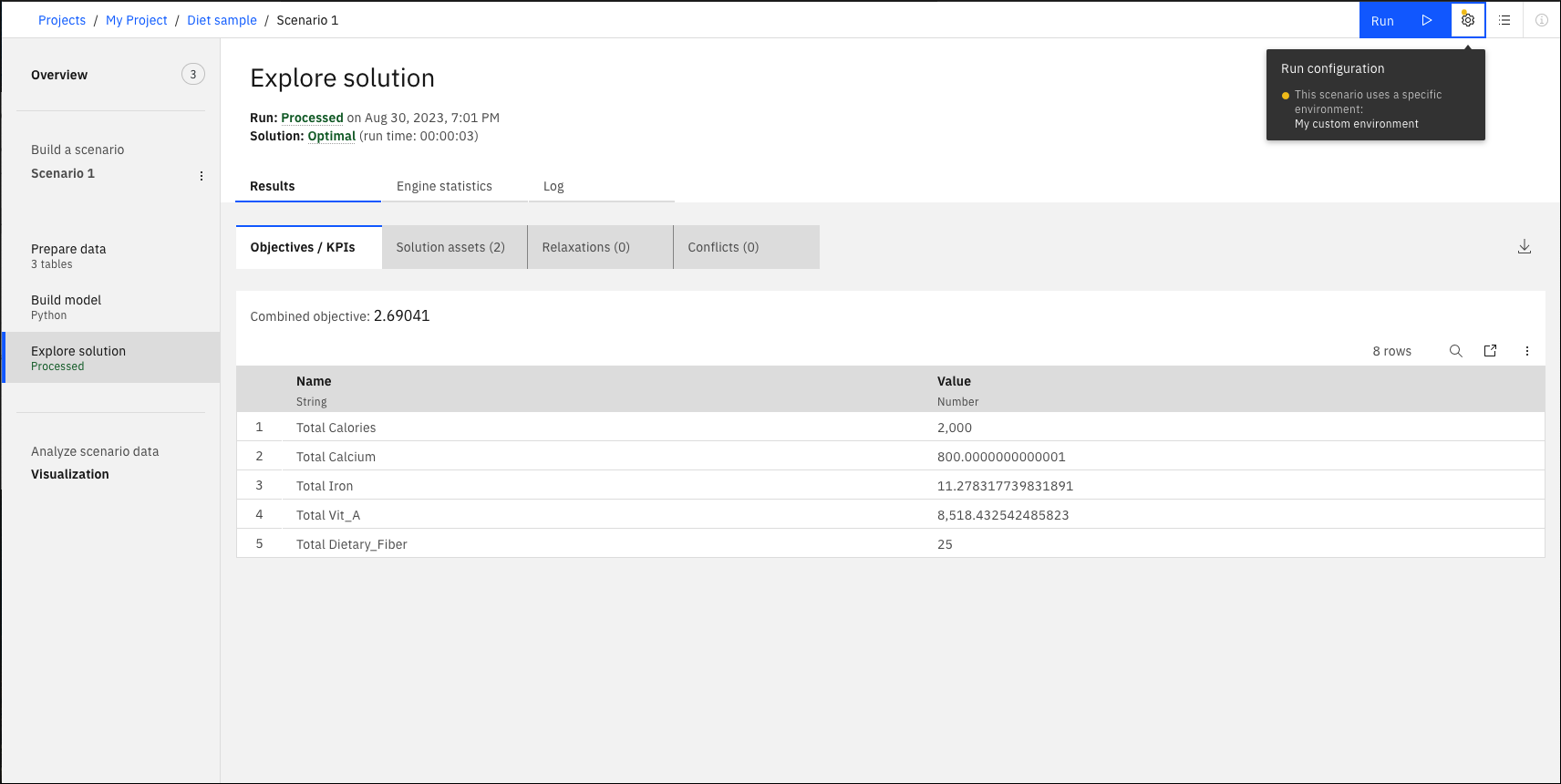
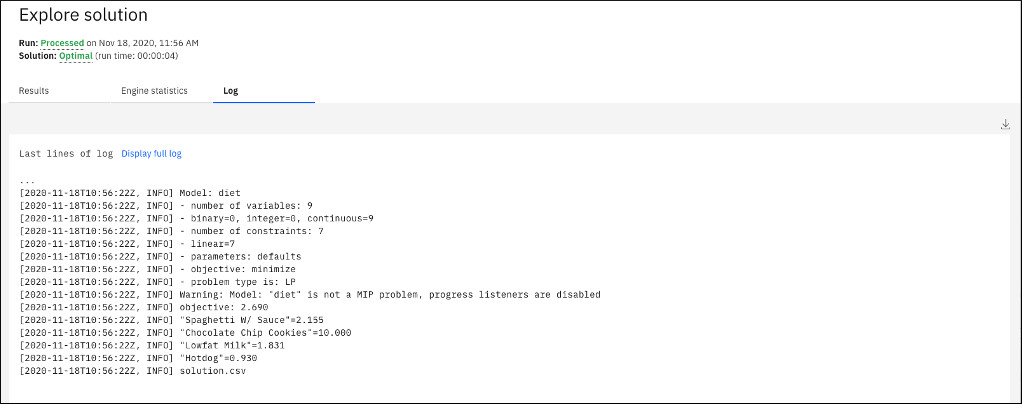
Po pomyślnym wykonaniu rozwiązanie zostanie wyświetlone w jednej lub kilku tabelach lub jako plik dla modeli CPLEX i CPO w Poznaj rozwiązanie Widok.
Sekcja Wyniki zawiera kilka kart. Pierwsza karta przedstawia cele i kluczowe wskaźniki wydajności. Na karcie Tabele rozwiązań wyświetlane są wynikowe (najlepsze) wartości zmiennych decyzyjnych. Te tabele rozwiązań są automatycznie wyświetlane w kolejności alfabetycznej. Należy zauważyć, że tych tabel rozwiązania nie można edytować, ale można je filtrować. Patrz sekcja Wyszukiwanie i filtrowanie tabeli. Można pobrać zarówno tabele celów, jak i rozwiązania. W przypadku modeli CPLEX i CPO rozwiązania nie są dostępne w tabelach, ale w plikach, które można pobrać.
Można zdefiniować tabele wynikowe, które będą wyświetlane w tym widoku w modelu Python DOcplex , w którym używana jest składnia outputs['tablename'], patrz sekcja Dane wejściowe i wyjściowe.
Karty Relakacje i Konflikty wskazują, czy w modelu istniały jakiekolwiek ograniczenia lub ograniczenia powodujące konflikt. Ponadto, jeśli te opcje zostały wybrane, na tych kartach znajdują się informacje o ograniczeniach i ograniczeniach, które zostały rozluźnione w celu rozwiązania modelu.
Na karcie Statystyka mechanizmu wyświetlane są informacje o statusie uruchomienia (przetworzony, zatrzymany lub niepowodzenie), informacje graficzne o rozwiązaniu i statystyki modelu. Powiększenie wykresu można wykonać, przesuwając punkty końcowe poziomego paska powiększania lub zaznaczając obszar na wykresie. Aby przywrócić oryginalny wykres po powiększeniu, można w pełni rozwinąć pasek powiększenia lub odświeżyć stronę.
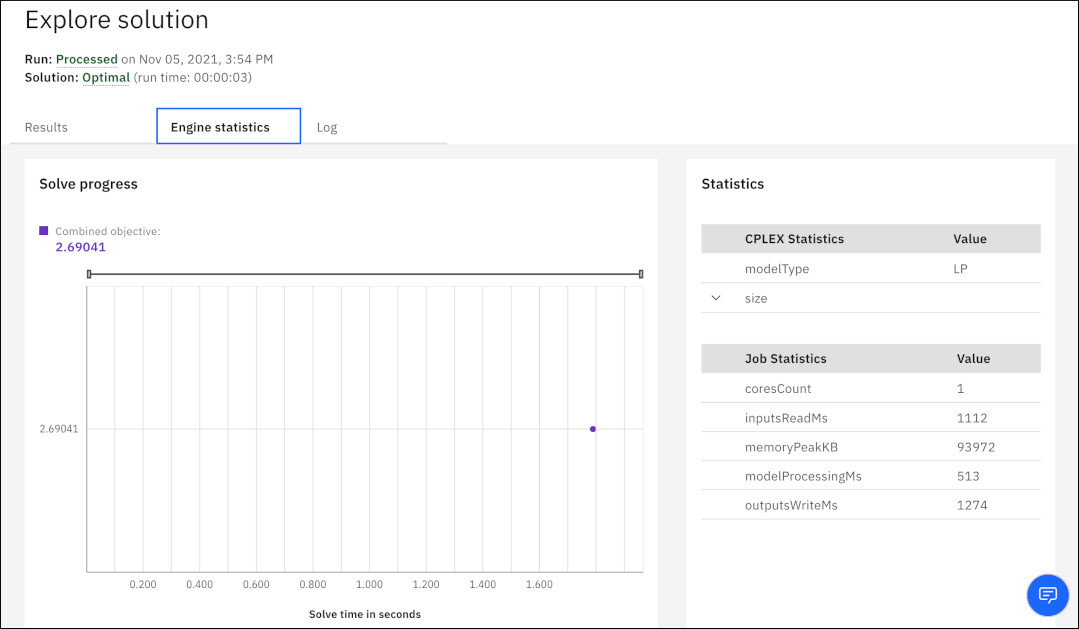
Na karcie Dziennik wyświetlany jest plik dziennika z mechanizmów CPLEX lub CP Optimizer, który można również pobrać.
W przypadku modeli z wieloma celami sformułowanych za pomocą Modeling Assistantw tabeli rozwiązania wyświetlane są również suwaki, wagii czynniki skali , które zostały ustawione w modelu. Połączony cel strategiczny jest sumą wszystkich wartości celu strategicznego (dodatnie wartości dla zminimalizowania celów strategicznych i ujemne dla maksymalizacji celów strategicznych) pomnożoną przez współczynnik skali (domyślnie 1) i współczynnik wagi. Współczynnik wagi wynosi 2 do potęgi wagi suwaka minus 1. Na przykład dla suwaka wagi 5 współczynnik wagi wynosi 25-1= 24= 16. Skalowana wartość ważona jest zatem wartością funkcji celu pomnożoną przez ten czynnik wagi.
Aby uruchomić modele, należy powiązać instancję produktu Watson Machine Learning z projektem i powiązać obszar wdrażania z eksperymentemproduktu Decision Optimization . Użytkownik musi mieć również rolę Edytujący lub Administrator w obszarze wdrażania.
Pliki można eksportować z tego widoku. Patrz sekcja Eksportowanie danych.
Panel Scenariusz
Podczas tworzenia nowego eksperymentu Decision Optimization scenariusz jest tworzony automatycznie wraz z modelem. Scenariusz zawiera zestawy danych, model i rozwiązanie.
- Upewnij się, że konkretny model działa z różnymi danymi.
- Zobacz, jak różne zestawy danych wpływają na rozwiązanie problemu.
- Zobacz, jak sformułowanie modelu wpływa na rozwiązanie problemu.
- Zapisz scenariusz jako model do wdrożenia (wszystkie parametry konfiguracji uruchamiania, które mogły zostać ustawione dla tego scenariusza, są również zapisywane we wdrożeniu). Więcej informacji na ten temat zawiera sekcja Wdrażanie modelu Decision Optimization za pomocą interfejsu użytkownika .
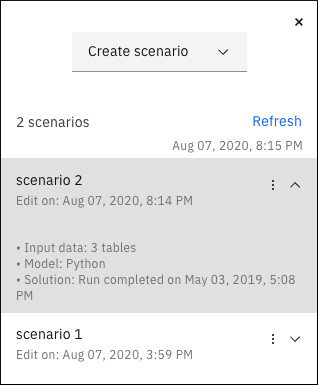
Z poziomu panelu Scenariusz można łatwo zarządzać różnymi scenariuszami Decision Optimization eksperyment.
Aby otworzyć panel scenariuszy, kliknij przycisk Otwórz panel scenariuszy  .
.
- Utwórz nowe scenariusze (utwórz nowy scenariusz od podstaw, zduplikuj bieżący scenariusz lub zaimportuj nowy scenariusz z pliku).
- Wybierz scenariusz, w którym chcesz pracować.
- Zobacz istniejące scenariusze i ich szczegóły (dane wejściowe, model, rozwiązanie). Każdy z nich można rozwinąć lub zwinąć, klikając strzałkę obok scenariusza.
- Zarządzanie istniejącymi scenariuszami (duplikowanie, zmiana nazwy, usuwanie).
- Generowanie Python notatnik na podstawie scenariusza.
- Zapisz scenariusz jako model do wdrożenia (typy danych ustawione w Przygotowanie danych Widok i wszystkie parametry konfiguracji uruchamiania, które mogły zostać ustawione dla tego scenariusza, są również zapisywane we wdrożeniu). Więcej informacji na ten temat zawiera sekcja Wdrażanie modelu Decision Optimization za pomocą interfejsu użytkownika .
- Wyeksportuj scenariusz jako plik
.zip.
Po kliknięciu przycisku Wygeneruj notebook ze scenariusza, notatnik zostanie zapisany jako zasób aplikacyjny w projekcie. Jeśli użyto parametru wiele plików w Budowanie modelu Widok, te pliki są automatycznie przywoływane w wygenerowanym pliku notatnik , dzięki czemu można je odczytać z pliku notatnik. Wersja Python dla wygenerowanego notatnika zależy od środowiska, które zostało skonfigurowane dla scenariusza. Patrz sekcja Konfigurowanie środowisk. Jeśli środowisko zostało automatycznie utworzone dla scenariusza, notatnik używa domyślnej wersji Python 3.10.
Po kliknięciu opcji Eksportuj jako plik zipw archiwum zostanie również umieszczony plik scenario.json opisujący wyeksportowany model. Jeśli zmiany zostaną wprowadzone lokalnie w tym scenariuszu (na przykład do modelu zostanie dodana tabela), można edytować plik json , aby uwzględnić te zmiany. Następnie można ponownie zaimportować scenariusz i te zmiany zostaną wyświetlone w scenariuszu.
Nowe scenariusze można zaimportować , wybierając opcję Z pliku w menu Utwórz scenariusz , a następnie wybierając plik .zip zawierający nowy scenariusz.
Można również użyć tej metody do utworzenia nowego scenariusza z wygenerowanego pliku debugowania .zip (patrz sekcja Parametry niestandardowe) i pobranego pliku. Plik debugowania .zip udostępnia scenariusz, który zawiera dane, model, rozwiązanie i parametry konfiguracji uruchamiania.
Można przełączać scenariusze podczas uruchamiania modelu i wyświetlać w panelu scenariuszy, które scenariusze są uruchomione lub są w kolejce.
Kliknięcie strzałki obok scenariusza w tym panelu powoduje również wyświetlenie informacji podsumowujących o danych, modelu i rozwiązaniu.
W scenariuszu używane jest domyślne środowisko wykonawcze , które zostało utworzone dla tego typu modelu. Tę wartość domyślną można wyświetlić na karcie Przegląd w panelu Informacje Środowisko . Więcej informacji na ten temat zawiera sekcja Konfiguracja sprzętu i oprogramowania oraz sekcja Konfigurowanie środowisk. Aby zmienić środowisko wykonawcze dla konkretnego scenariusza, należy zapoznać się z sekcją Wybór innego środowiska wykonawczego dla konkretnego scenariusza.