STSA Data Visualization With Python¶

NASA TERRA MODIS INFRARED IMAGE OF HARVEY AT 0419 UTC 26 AUGUST 2017 JUST AFTER LANDFALL AS A CATEGORY 4 HURRICANE IN TEXAS. IMAGE COURTESY OF UW/CIMSS.
A Jupyter Notebook used to visualize data from the Houston Flood of 2017 running on IBM Watson Studio¶
Jupyter Notebook¶
An open-source web application that allows you to create and share documents that contain live code, equations, visualizations and narrative text. Uses include: data cleaning and transformation, numerical simulation, statistical modeling, data visualization, machine learning, and much more.
IBM Watson Studio¶
Build and train AI & machine learning models, prepare and analyze data – all in a flexible, hybrid cloud environment IBM Watson Studio provides tools for data scientists, application developers and subject matter experts to collaboratively and easily work with data to build and train models at scale. It gives you the flexibility to build models where your data resides and deploy anywhere in a hybrid environment so you can operationalize data science faster.
Python¶
Python is a programming language that lets you work quickly and integrate systems more effectively.
1.0 Install dependencies and import packages¶
1.1 Install pixiedust¶
We install the prerequisites using the !pip install syntax here.
In some cases, running pip install from a notebook may require a one-time kernel restart. Check the output for messages.
If instructed to restart the kernel, from the notebook toolbar menu: • Go to > Kernel > Restart • Click Restart in the confirmation dialog
Note: The status of the kernel briefly flashes near the upper right corner, alerting when it is Not Connected, Restarting, Ready, etc.
!pip install --upgrade pixiedust
Collecting pixiedust Collecting geojson (from pixiedust) Using cached https://files.pythonhosted.org/packages/f1/34/bc3a65faabce27a7faa755ab08d811207a4fc438f77ef09c229fc022d778/geojson-2.4.1-py2.py3-none-any.whl Collecting astunparse (from pixiedust) Using cached https://files.pythonhosted.org/packages/2e/37/5dd0dd89b87bb5f0f32a7e775458412c52d78f230ab8d0c65df6aabc4479/astunparse-1.6.2-py2.py3-none-any.whl Collecting lxml (from pixiedust)
import pandas as pd
import pixiedust
2.0 Obtain and curate data¶
In order to do data science, or data engineering, we'll need some data. So, what problem are we trying to solve?
Where in Houston does flooding occur, and which specific adresses are vulnerable?¶
2.1 Search for data¶
We are interested in the flooding in Houston on August, 2017, as a result of Hurricane Harvey.
Using a search engine, we can try houston flood 2017 data.
That gave many results, mostly news stories. But there are some promising sites, many from US government agencies:
- https://www.weather.gov
- https://txpub.usgs.gov/floodwatch/#page-top
- https://water.weather.gov/ahps2/index.php?wfo=hgx
- https://www.nhc.noaa.gov/data/tcr/AL092017_Harvey.pdf
- https://stn.wim.usgs.gov/STNDataPortal/#
- https://streamstats.usgs.gov/ss/
That's just the beginning, but hopefully it can lead to some data we can use.
2.2 Download and examine data¶
We'll look at some data from stream gauges in Houston, gathering historical data from the dates 8/23/2017 - 8/31/2017.
I've grabbed the data for one stream gauge in the Houston Beltway area, Hunting Bayou, from the waterdata.usgs.gov site.
!wget https://raw.githubusercontent.com/IBM/visualize-data-with-python/master/data/HuntingBayou.csv
2.3 First, let's look at the header to the file (which I've peeked at in an editor). This gives us some info on the contents:¶
! head -n 35 HuntingBayou.csv
2.4 Look at the pandas dataframe¶
I see from the header that I need to skip the first 29 rows (rows 0-28), that the data is tab separated, and the header begins on the 30th line (line 29).
df = pd.read_csv('HuntingBayou.csv',sep='\t',skiprows=(0-28),header=(29))
df.head()
2.5 Do some data frame cleanup¶
What's with the extra fields on line 0? Let's delete that line.
df = df.drop(0)
We can rename those obscure column names, to give them a name that represents the data:
df.rename(columns={'140488_00060': 'Discharge(cfs)', '140489_00065': 'GuageHeight(feet)'}, inplace=True)
Let's replace the site_no with a site_name for HuntingBayou.csv:
df.rename(columns={'site_no': 'site_name'}, inplace=True)
df['site_name'].replace("08075770", "HuntingBayou.csv", inplace=True)
We don't care about the first agency_cd column, which is USGS, so let's drop it. The same goes for the 140488_00060_cd, 140489_00065_cd, and tz_cd columns. The axis=1 denotes that this is a column.
df.drop(['agency_cd', '140488_00060_cd', '140489_00065_cd', 'tz_cd'], axis=1, inplace=True)
Our Discharge and GuageHeight data are strings, but we need them to be floats. We'll convert them
df['GuageHeight(feet)'] = df['GuageHeight(feet)'].convert_objects(convert_numeric=True)
df['Discharge(cfs)'] = df['Discharge(cfs)'].convert_objects(convert_numeric=True)
Our datetime has the year 2017 for all fields, but our graphs will be cleaner if we skip it
df['datetime'] = df['datetime'].map(lambda x: x.lstrip('2017-'))
And finally, we can get the latitude and longitude for this stream gauge at Hunting Bayou, so let's add a couple columnns with that data, to allow this to show up on a map. We'll need that lat/long in decimal, so find a tool for that as well.
df['latitude']='29.808611'
df['longitude']='-95.313056'
Now we can see our results.
df.head()
2.6 Use Matplotlib to visualize data¶
Matplotlib is a Python 2D plotting library which produces publication quality figures in a variety of hardcopy formats and interactive environments across platforms. Matplotlib can be used in Python scripts, the Python and IPython shells, the Jupyter notebook, web application servers, and four graphical user interface toolkits.
We'll use the inline backend to plot the graph in the notebook.
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
Plot the Discharge against time¶
# setup line graph
plt.plot(df['datetime'],df['Discharge(cfs)'])
plt.title('Houston Flood discharge at Hunting Bayou stream gauge')
plt.ylabel('Discharge(cfs)')
plt.xlabel('datetime')
ax = plt.gca()
df.set_index('datetime')
# Only label every 20th value
ticks_to_use = df.index[::100]
# label ticks per day
dr = pd.date_range('2017-08-23', periods=9, freq='D')
## Now set the ticks and labels
ax.set_xticks(ticks_to_use)
ax.set_xticklabels(dr)
plt.xticks(rotation='vertical')
plt.show()
Plot the Gauge Height against time¶
# setup line graph
plt.plot(df['datetime'],df['GuageHeight(feet)'])
plt.title('Houston Flood Gauge Height at Hunting Bayou stream gauge')
plt.ylabel('GuageHeight(feet)')
plt.xlabel('datetime')
ax = plt.gca()
df.set_index('datetime')
# Only label every 20th value
ticks_to_use = df.index[::100]
# label ticks per day
dr = pd.date_range('2017-08-23', periods=9, freq='D')
## Now set the ticks and labels
ax.set_xticks(ticks_to_use)
ax.set_xticklabels(dr)
plt.xticks(rotation='vertical')
plt.show()
Plot the stream Gauge Height against time
2.7 Use pixiedust display() to explore the schema and browse the data¶
With ther pixiedust helper library, we can display charts and graphs more easily, with the one-line display() method.
2.7.1 Select DataFrame Table icon in the display widget to see the data in tabular form¶

2.7.2 Select the chart icon to pull down and choose line chart. Click the Options button, and then for Keys drag and drop datetime and for Values drag and drop Discharge. This will display the water discharge at this stream gauge in cubic feet per second.¶

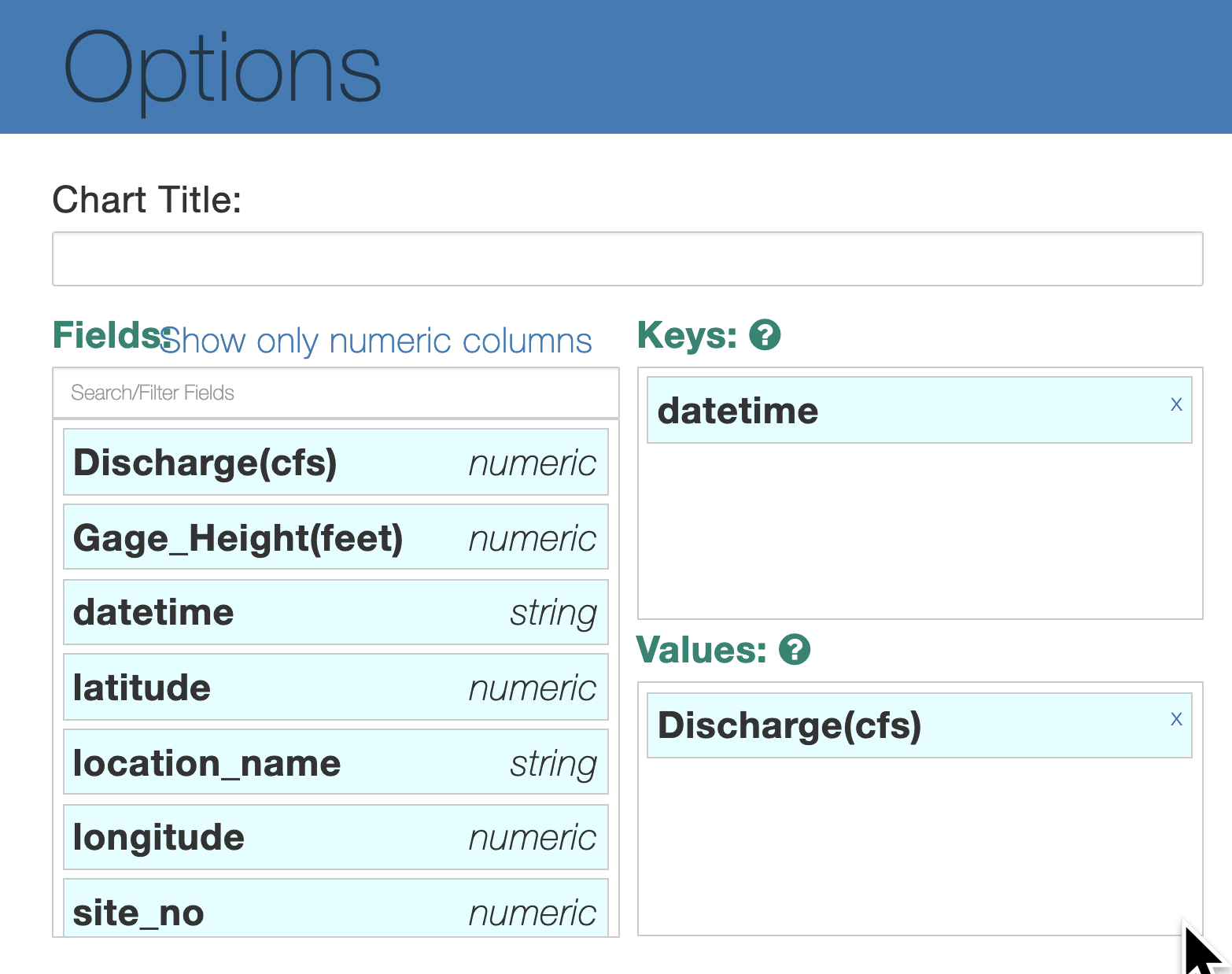
2.7.4 Click the Options button, and then for Keys drag and drop datetime and for Values drag and drop Gauge_Height. This will display the height of the water at this stream gauge, in feet.¶
hunting = df
display(hunting)
2.8 Gather data for Max stream flows¶
We have already:¶
- Found data we can use
- Cleaned the data
- Displayed the data
Next, let's aggregate stream Gauge Maximums for Gauge Height and Discharge so that we can put them on a map.
This is done offline, manually using a text editor after downloading from various stream gauges, and then put into a single file.
!wget https://raw.githubusercontent.com/IBM/visualize-data-with-python/master/data/maxFlood.csv
maxFlood = pd.read_csv('maxFlood.csv')
maxFlood
display(maxFlood)
3.0 Create Pixie App¶
Building the PixieApp Dashboard¶
What you'll need:¶
- Mapbox token: A Mapbox token is rquired for the notebook. To get your own visit Mapbox
- Mapbox layers Documentation: circle, fill, symbols
- Mapbox Maki Icons: https://www.mapbox.com/maki-icons
- Browse the data from Huricane Harvey data archives to get the GeoJSON url
- Some understanding of Jinja2 template
- A Quick read of PixieApp documentation
FAQ about the code below:¶
- How do I get the pixiedust options in
self.mapJSONOptions?
- Call
display()on a new cell- Graphically select the options for your chart
- Select "View"/"Cell Toolbar"/"Edit Metadata" menu
- Click on the “Edit Metadata” button and copy the pixiedust metadata
- What's the
self.setLayerscall for?
This is a method from the MapboxBase class used to specify the custom layer definitions array.
The fields are:
- name: Layer name
- url: geojson url to download the data from
- type: (optional) style type e.g Symbol. If not defined, then default value will be infered from geojson geometry
- paint: (optional) paint style, see appropriate documentation e.g. circle
- layout: (optional) layout style, see appropriate documentation e.g. fill
- How do I find new layer data to add?
The data layers use geojson format. If you have a
.csvfile, you can use a csv to geojson converter to format correctly.
- What does the
mainScreenmethod do?
This is a PixieApp View associated with the default route. See PixieApp documentation for more information.
- What's the {{...}} notation in the mainScreen markup for?
This is a Jinja2 template notation to call server side Python code. See Jinja2 template for more info
- How to turn CSV (comma separated values) into geojson?
There's an app for that!
!wget https://raw.githubusercontent.com/IBM/visualize-data-with-python/master/data/streamGauges.geojson
from pixiedust.display.app import *
from pixiedust.apps.mapboxBase import MapboxBase
@PixieApp
class HoustonDashboard(MapboxBase):
def setup(self):
self.mapJSONOptions = {
"colorrampname": "Green to Purple",
"coloropacity": "100",
"handlerId": "mapView",
"kind": "simple",
"mapboxtoken": "",
"keyFields": "latitude,longitude",
"valueFields": "Gage_Height(feet),Discharge(cfs),date,time"
}
self.setLayers([
{
"name": "Houston Flooded Streets",
"url": "https://raw.githubusercontent.com/IBM/visualize-data-with-python/master/data/houston.geojson",
"type": "LineString"
},
{
"name": "Random fictional homes",
"url": "https://raw.githubusercontent.com/IBM/visualize-data-with-python/master/data/HoustonFloodedZips250.geojson",
"circle-color": "rgb(0, 255, 0)"
}
])
def formatOptions(self,options):
return ';'.join(["{}={}".format(key,value) for (key, value) in iteritems(options)])
@route()
def mainScreen(self):
return """
<div class="well">
<center><span style="font-size:x-large">Analyzing Houston Flood data with PixieDust</span></center>
</div>
<div class="row">
<div class="form-group col-sm-2" style="padding-right:10px;">
<div><strong>Layers</strong></div>
{% for layer in this.layers %}
<div class="rendererOpt checkbox checkbox-primary">
<input type="checkbox" pd_refresh="map{{prefix}}" pd_script="self.toggleLayer({{loop.index0}})">
<label>{{layer["name"]}}</label>
</div>
{%endfor%}
</div>
<div class="form-group col-sm-10">
<div id="map{{prefix}}" pd_entity pd_options="{{this.formatOptions(this.mapJSONOptions)}}"/>
</div>
</div>
"""
HoustonDashboard().run(maxFlood,runInDialog="false")
4.0 Use Folium for mapping¶
Folium is a powerful Python library that helps you create several types of Leaflet maps. The fact that the Folium results are interactive makes this library very useful for dashboard building.
From the official Folium documentation page:
Folium builds on the data wrangling strengths of the Python ecosystem and the mapping strengths of the Leaflet.js library. Manipulate your data in Python, then visualize it in on a Leaflet map via Folium.
Folium makes it easy to visualize data that's been manipulated in Python on an interactive Leaflet map. It enables both the binding of data to a map for choropleth visualizations as well as passing Vincent/Vega visualizations as markers on the map.
The library has a number of built-in tilesets from OpenStreetMap, Mapbox, and Stamen, and supports custom tilesets with Mapbox or Cloudmade API keys. Folium supports both GeoJSON and TopoJSON overlays, as well as the binding of data to those overlays to create choropleth maps with color-brewer color schemes.
!pip install folium==0.5.0
4.1 Create map with Folium¶
Generating the world map is straigtforward in Folium. You simply create a Folium Map object and then you display it.
What is attactive about Folium maps is that they are interactive, so you can zoom into any region of interest despite the initial zoom level.
You can customize this default definition of the world map by specifying the centre of your map and the intial zoom level.
All locations on a map are defined by their respective Latitude and Longitude values.
So you can create a map and pass in a center of Latitude and Longitude values of [0, 0].
For a defined center, you can also define the intial zoom level into that location when the map is rendered.
The higher the zoom level the more the map is zoomed into the center.
import folium
# define the world map centered around Canada with a higher zoom level
houston_map = folium.Map(location=[29.808611, -95.313056], zoom_start=8)
# display world map
houston_map
4.2 Change Folium tiles¶
One feature of Folium is that you can create different map styles.
Test some changes to the map instantiation above by using:
world_map = folium.Map(location=[29.808611, -95.313056], zoom_start=8, tiles='Stamen Terrain')
OR
world_map = folium.Map(location=[29.808611, -95.313056], zoom_start=8, tiles='Stamen Toner')
OR
world_map = folium.Map(location=[29.808611, -95.313056], zoom_start=8, tiles='Mapbox Bright')
4.3 Add feature group¶
We can superimpose data from the 2017 Houston flood from stream gauges onto our Folium map
# instantiate a feature group for the incidents in the dataframe
gauges = folium.map.FeatureGroup()
# loop through the 100 crimes and add each to the incidents feature group
for lat, lng, in zip(maxFlood.latitude, maxFlood.longitude):
gauges.add_child(
folium.features.CircleMarker(
[lat, lng],
radius=5, # define how big you want the circle markers to be
color='yellow',
fill=True,
fill_color='blue',
fill_opacity=0.6
)
)
# add incidents to map
houston_map.add_child(gauges)
4.4 Add text and lat/long¶
You can also add some pop-up text that would get displayed when you hover over a marker. Let's make each marker display the stream gauge information.
Also, use folium.LatLngPopup() so that you can get latitude and logitude info when you click on the map
# instantiate a feature group for the stream gauges in the dataframe
gauges = folium.map.FeatureGroup()
# loop through the stream gauges and add each to the gauges feature group
for lat, lng, in zip(maxFlood.latitude, maxFlood.longitude):
gauges.add_child(
folium.features.CircleMarker(
[lat, lng],
radius=5, # define how big you want the circle markers to be
color='yellow',
fill=True,
fill_color='blue',
fill_opacity=0.6
)
)
# add site_name pop-up text to each marker on the map
latitudes = list(maxFlood.latitude)
longitudes = list( maxFlood.longitude)
label = list(maxFlood.site_name)
for lat, lng, label in zip(latitudes, longitudes, label):
folium.Marker([lat, lng], popup=label).add_to(houston_map)
# add gauges to map
houston_map.add_child(gauges)
# add clickable lat and long info
houston_map.add_child(folium.LatLngPopup())
houston_map.add_child(folium.ClickForMarker(popup='My House'))
5.0 Explore more tools¶
Investigate some othe Python libraries for data visualization:
open